ElasticSearch入门环境搭建(一)
本文最后更新于:2023年11月9日 晚上
ElasticSearch入门环境搭建(一)
ElasticSearch
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
- ElasticSearch版本7.9.3
- kibana版本7.9.3
- ik分词器版本7.9.3
安装ElasticSearch
1. 下面有两种下载方式:(官网下载堪比蜗牛,推荐大家使用第二种镜像的方式下载)
ElasticSearch官网下载: https://www.elastic.co/cn/elasticsearch
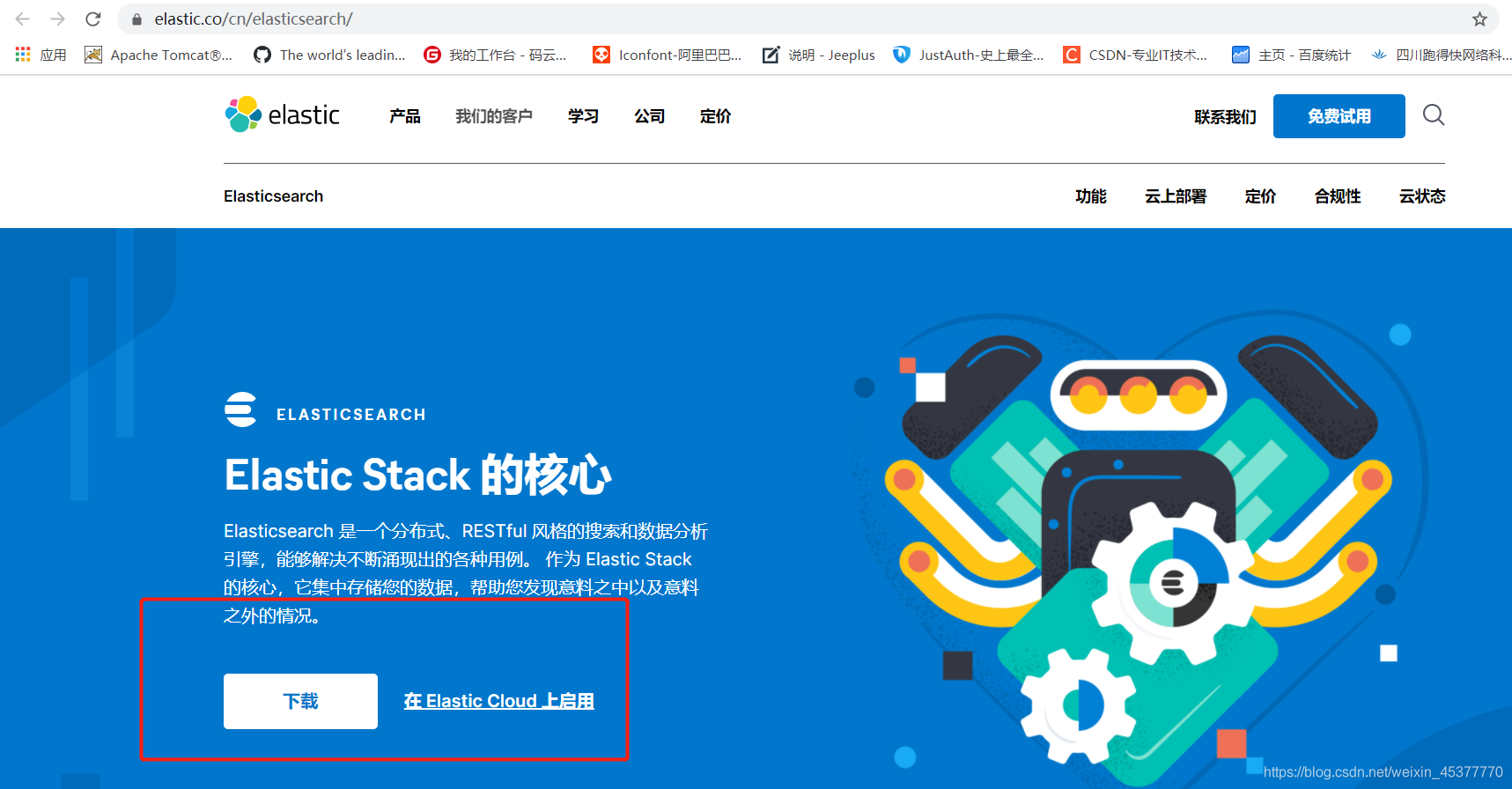
有不同的系统版本根据自己的情况下载就可以了
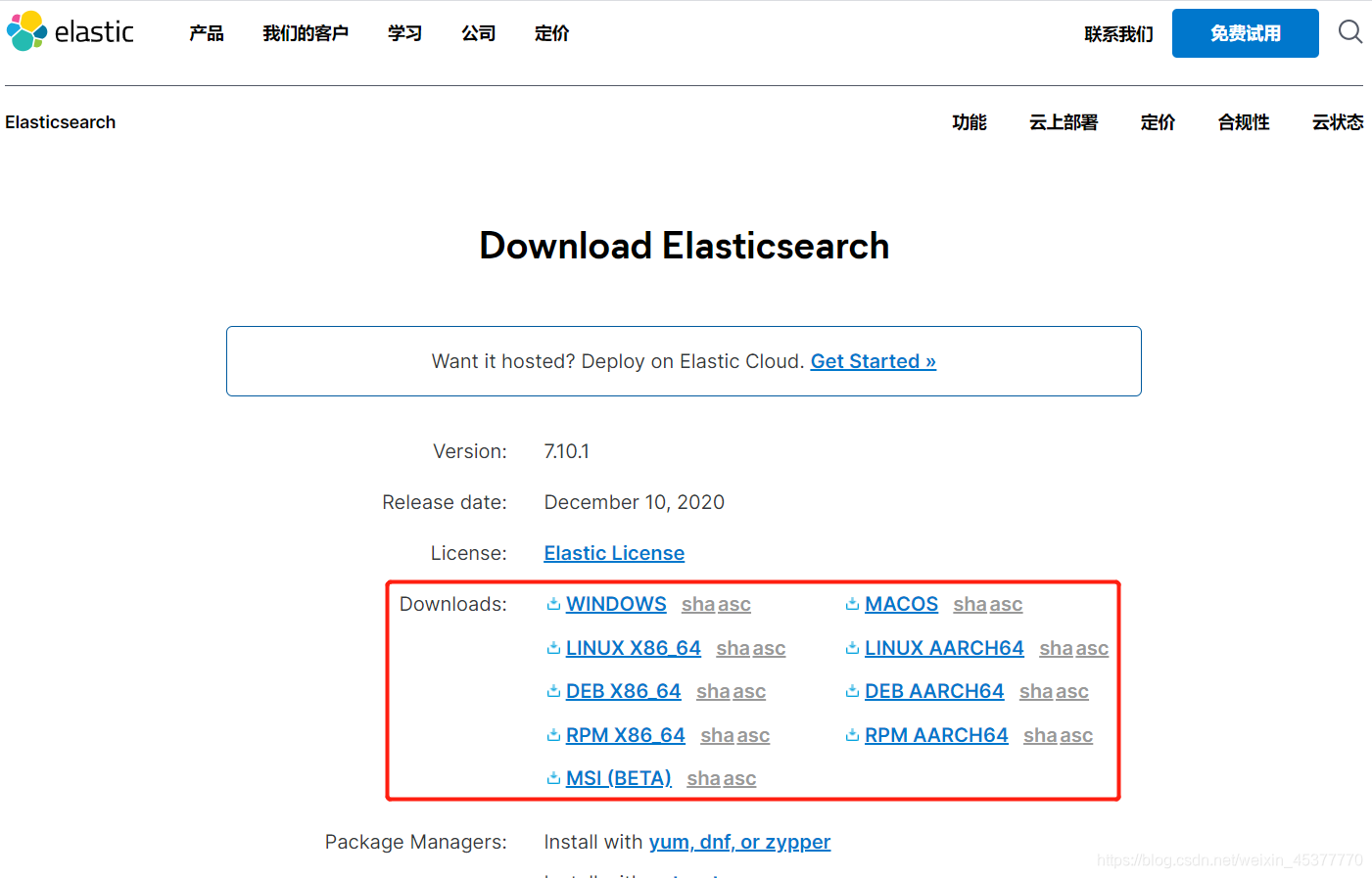
ElasticSearch华为云镜像下载:https://mirrors.huaweicloud.com/elasticsearch 最新的ElasticSearch版本在页面最下方
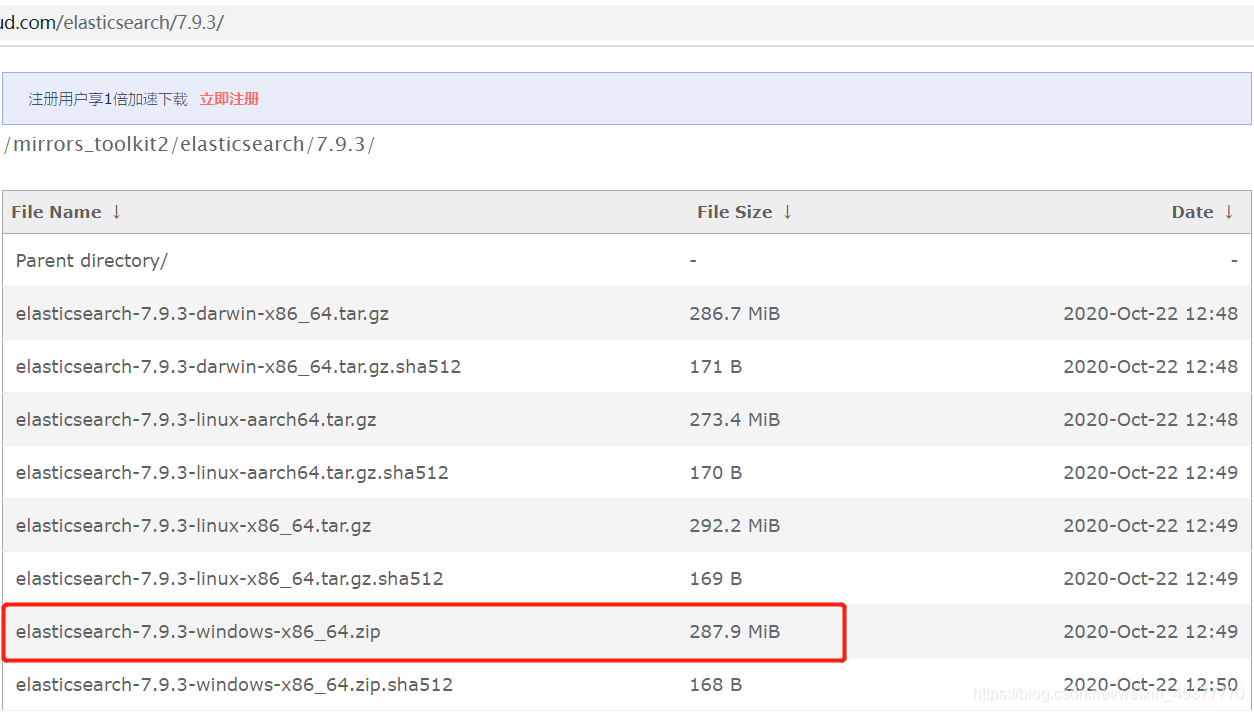
不同的版本,比如我们在windows下学习ElasticSearch选择windows64位版本就行了
2. 解将压缩包解压
- 来熟悉下目录
bin:二进制脚本,包含启动命令和安装插件命令等
comfig:配置文件(里面包含ElasticSearch、jvm、log4j等多个配置文件)
data:数据储存目录
lib:相关Jar依赖包
logs:日志文件
modules:功能模块
plugins:插件目录
3. 启动ElasticSearch
进入ElasticSearch的 bin 目录双击运行 elasticsearch.bat
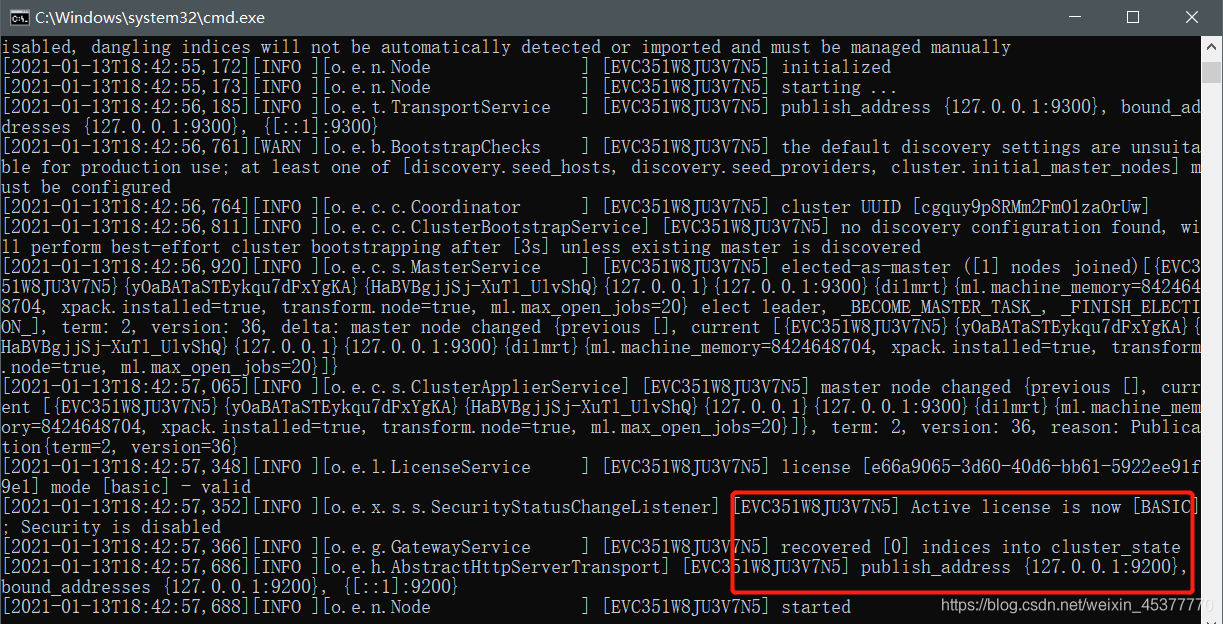
4. 测试访问ElasticSearch
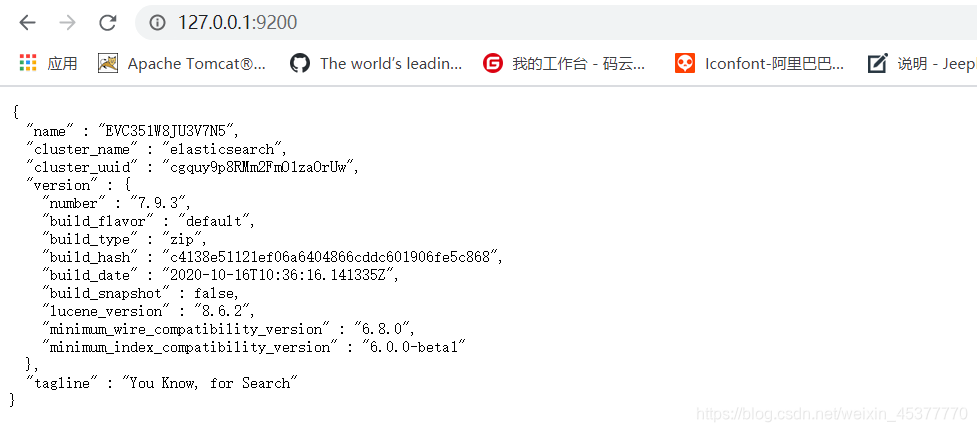
- ElasticSearch的默认端口为9200,启动完成后直接在浏览器中访问 127.0.0.1:9200
- 随后ElasticSearch就会返回JSON格式的一些基本信息
- 最后一个属性挺有意思:”tagline” : “You Know, for Search” 你知道的,为了搜索
安装可视化界面
下载elasticsearch-head:github地址 https://github.com/mobz/elasticsearch-head
1. 可以使用git命令下载:git clone https://github.com/mobz/elasticsearch-head
2. 或者直接点击下载ZIP的压缩包(不会真有人没安装git吧?百度自己去下载吧)
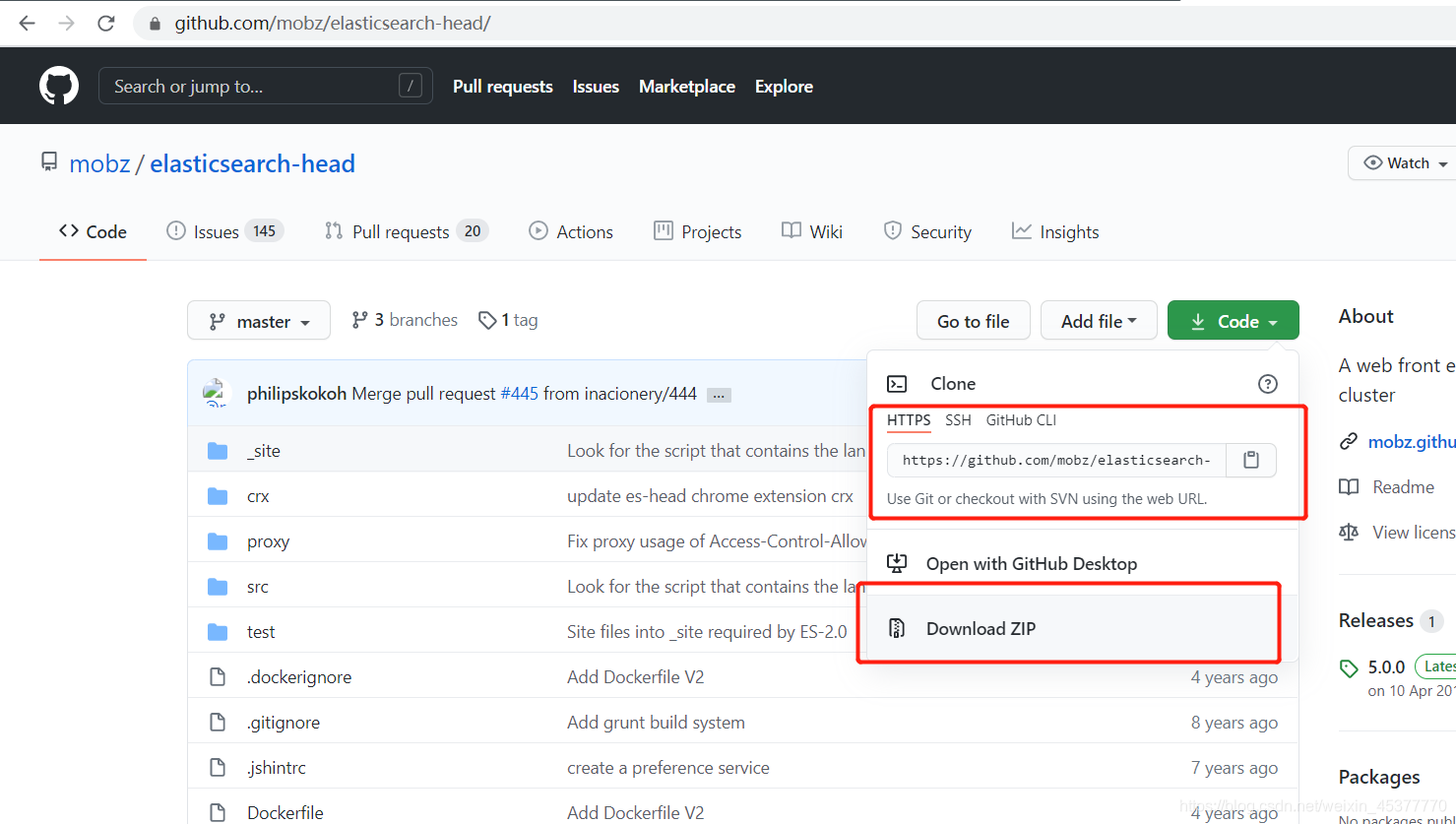
这里需要使用node.js进行项目初始化和导入依赖(如果没安装node.js的话,去官网下载安装即可,无需配置)
安装完后查看node以及npm是否安装成功
查看node.js版本:node -v 查看npm版本:npm -v

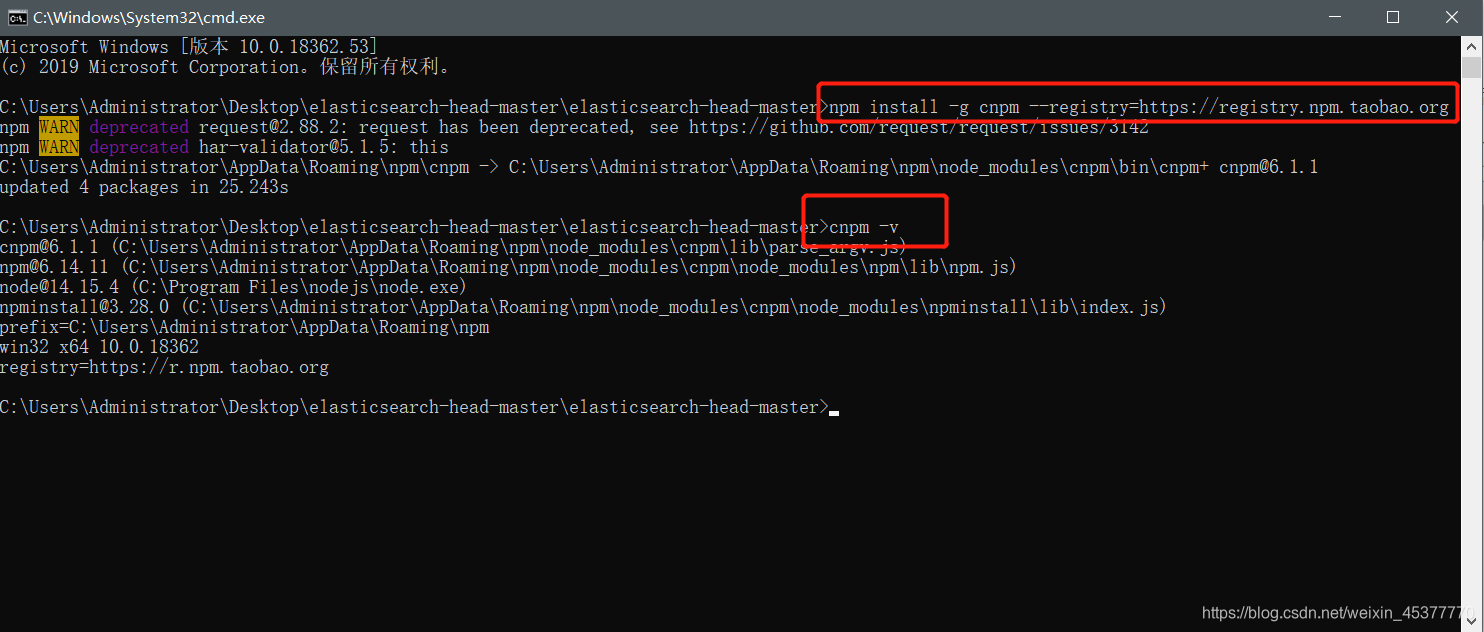
安装cnpm国内淘宝镜像(因为使用npm非常的慢)
命令:npm install -g cnpm –registry=https://registry.npm.taobao.org
安装完成cnpm后使用 cnpm -v 检查是否安装成功(如下图)
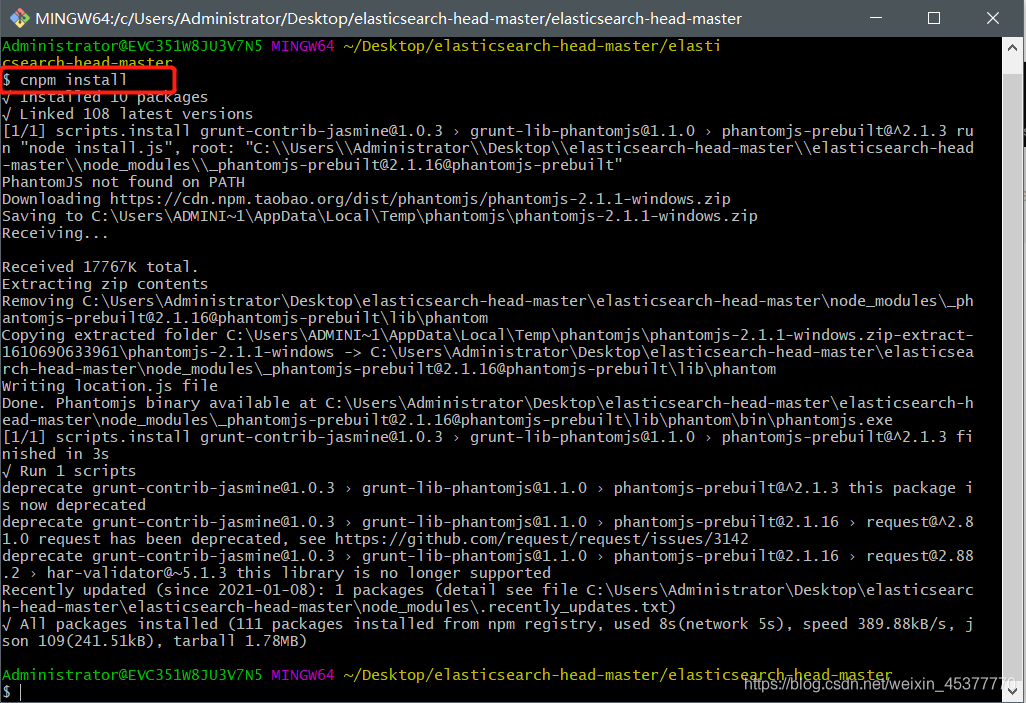
使用cmd或者git进入elasticsearch-head的目录下执行(文件名太长了这里使用git)
初始化elasticsearch-head这个项目模块 命令:cnpm install
运行此项目 命令:npm run start
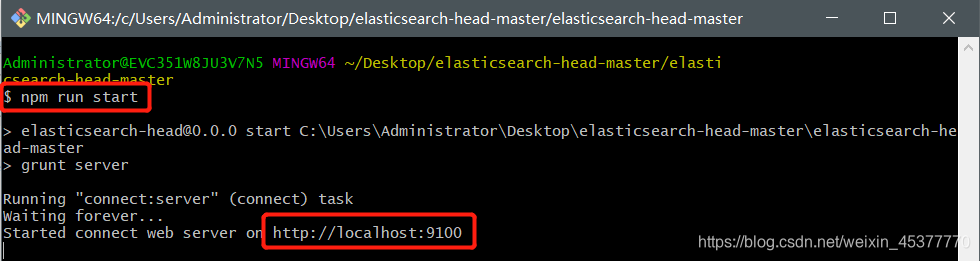
成功之后让我们去访问 http://localhost:9100(elasticsearch是9200,elasticsearch-head是9100)

我们安装好可视化界面后尝试连接下elasticsearch看看是否成功
无法连接到elasticsearch服务 其实一个是跨域的问题
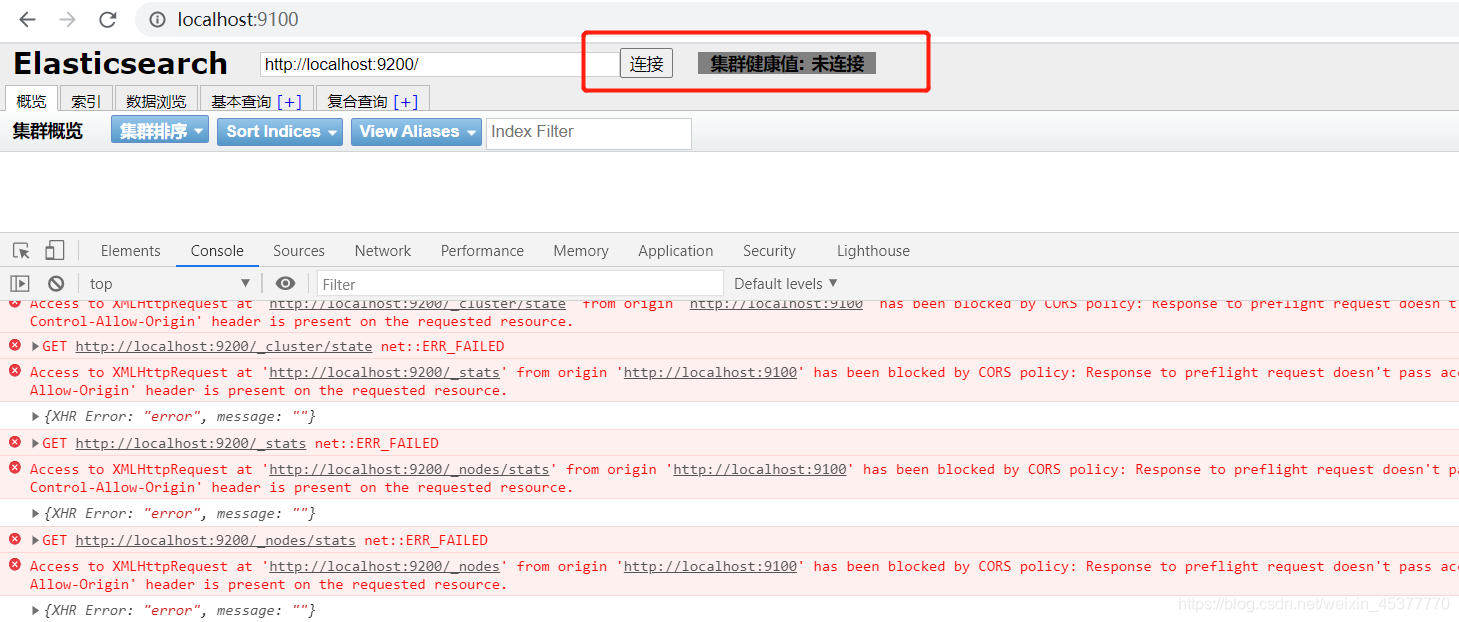
解决跨域问题
- 进入elasticsearch的config目录并打开elasticsearch.yml配置文件
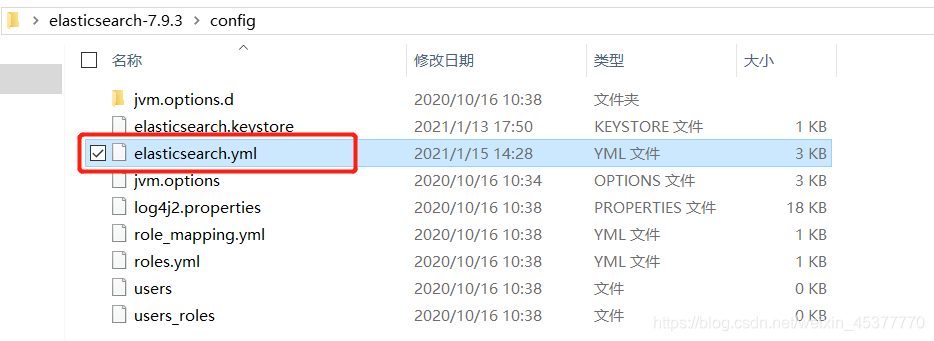
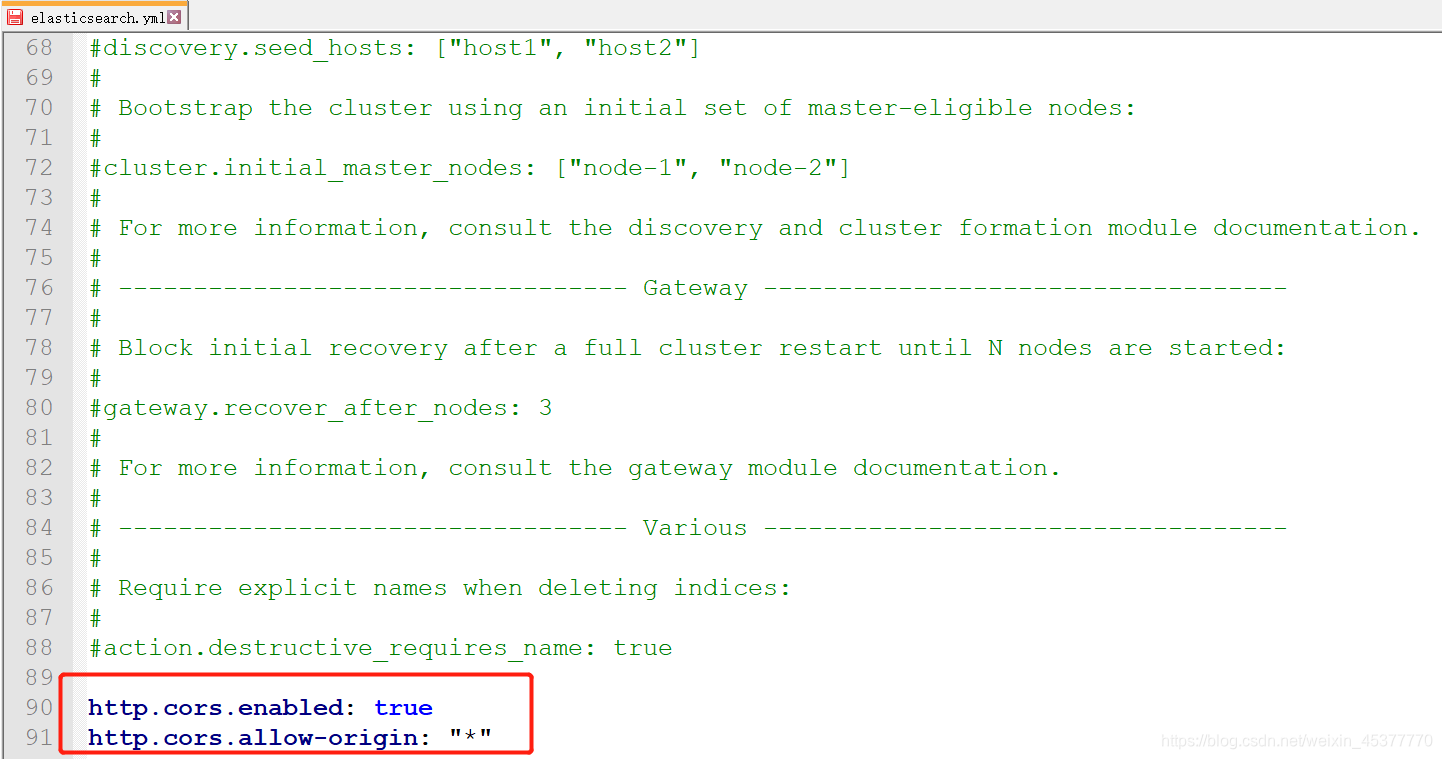
- 在后面加上此内容即可解决跨域问题
1 | |
- 重启elasticsearch 运行elasticsearch下bin目录的可执行文件elasticsearch.bat(在windows系统下直接双击即可)
- 再次使用elasticsearch-head尝试连接elasticsearch服务 成功
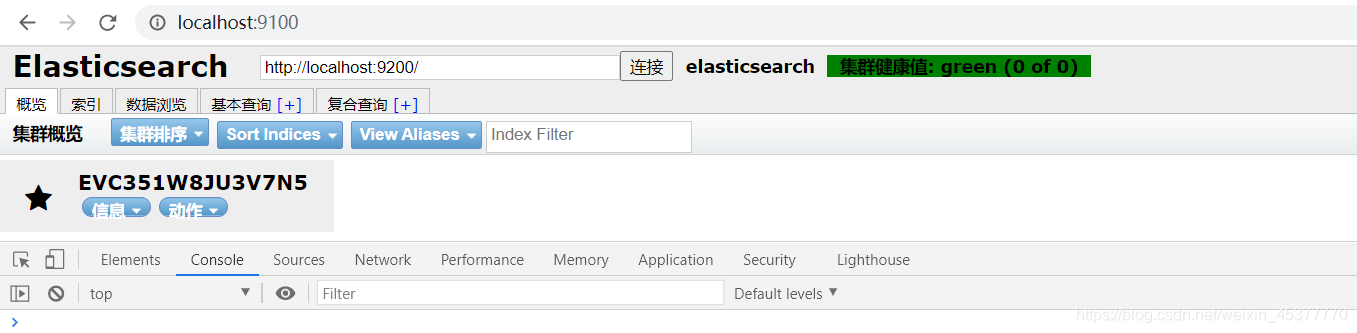
- 可以简单了解下elasticsearch-head的界面,后面再使用
安装kibana
kibana和elasticsearch都是拆箱即用,同样的下载分官方下载和华为云镜像下载。kibana也是如此(因为官方非常的慢)
kibana华为云镜像下载:https://mirrors.huaweicloud.com/kibana kibana官方地址: https://www.elastic.co/cn/kibana
注:kibana的版本一定要和elasticsearch版本一致 下载完成后解压需要一小段时间
访问kibana
kibana解压完成后进入bin目录双击kibana.bat运行

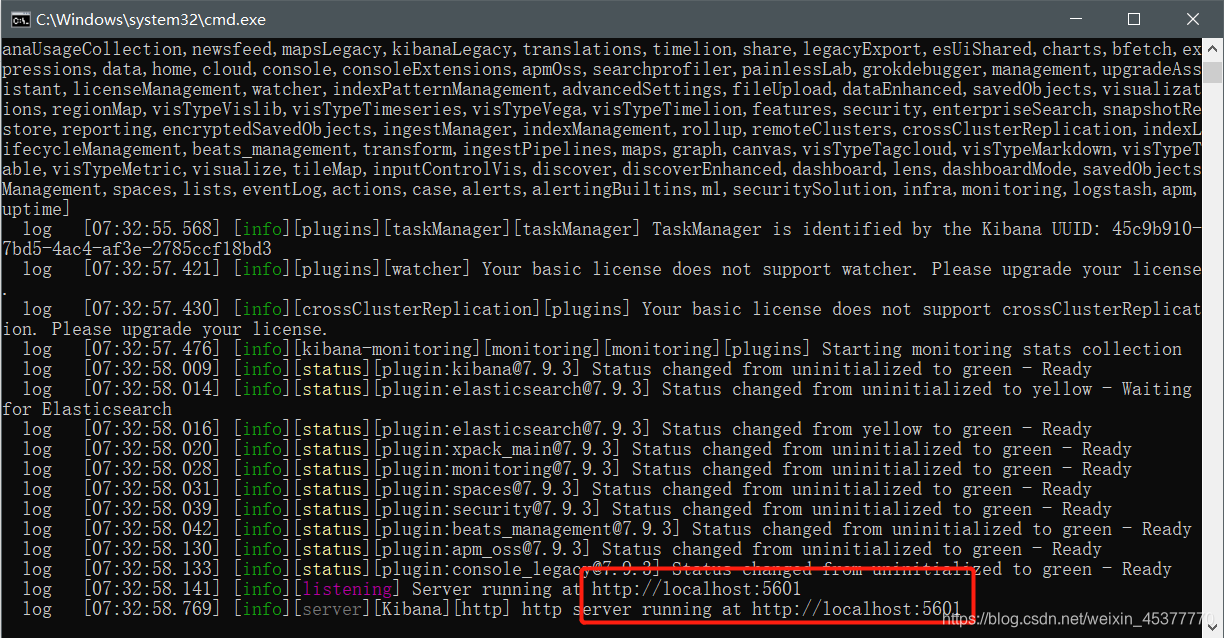
访问:http://localhost:5601(不同的kibana版本可能界面有所不同)
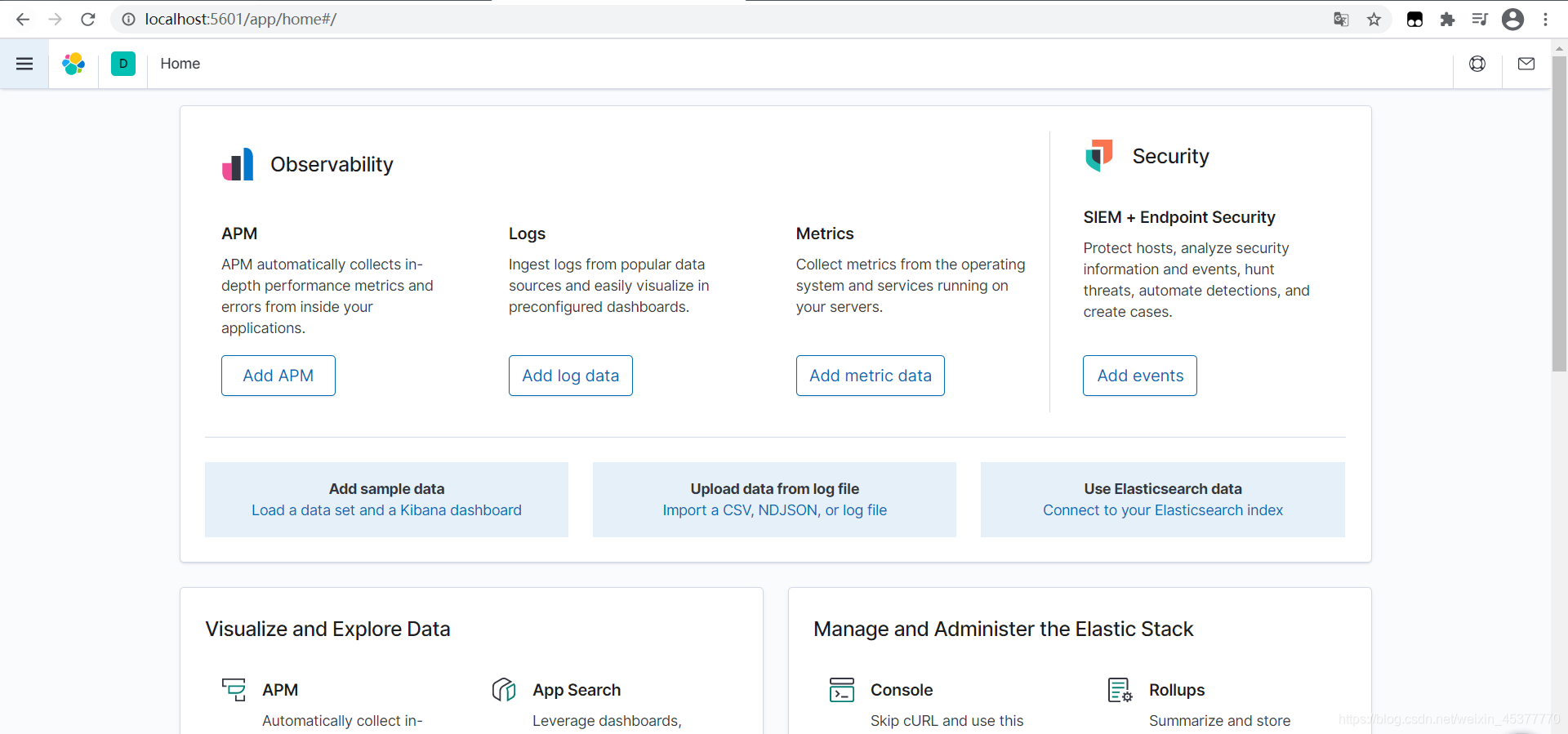
访问kibana后发现全是English,如果是中文看起来肯定最舒服,如何让kibana变成中文?我们接下来汉化kibana
- 汉化kibana
- 进入kibana的bin目录打开 kibana.yml文件

- 在最后一行加上: i18n.locale: “zh-CN”

- 关闭kibana窗口重新运行bin目录下kibana.bat文件再访问:http://localhost:5601 汉化成功
IK分词器
- 什么是IK分词器?
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词器是将每个字看成一个词,比如”我爱技术”会被分为”我”,”爱”,”技”,”术”,这显然不符合要求,所以我们需要安装中文分词器IK来解决这个问题
IK提供了两个分词算法:ik_smart和ik_max_word
其中ik_smart为最少切分,ik_max_word为最细粒度划分
- 安装IK分词器
**1. 下载IK分词器 github地址:https://github.com/medcl/elasticsearch-analysis-ik**(注意和elasticsearch版本对应)
2. 在elasticsearch的plugins目录下新建一个名为ik的文件夹,并将ik分词器压缩包解压到文件夹下面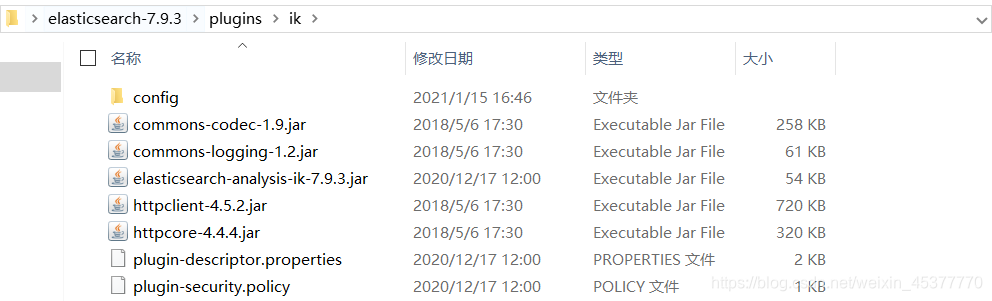
3. 重启elasticsearch,让它去加载ik分词器插件
在启动时就可以明确的看到加载了ik分词器插件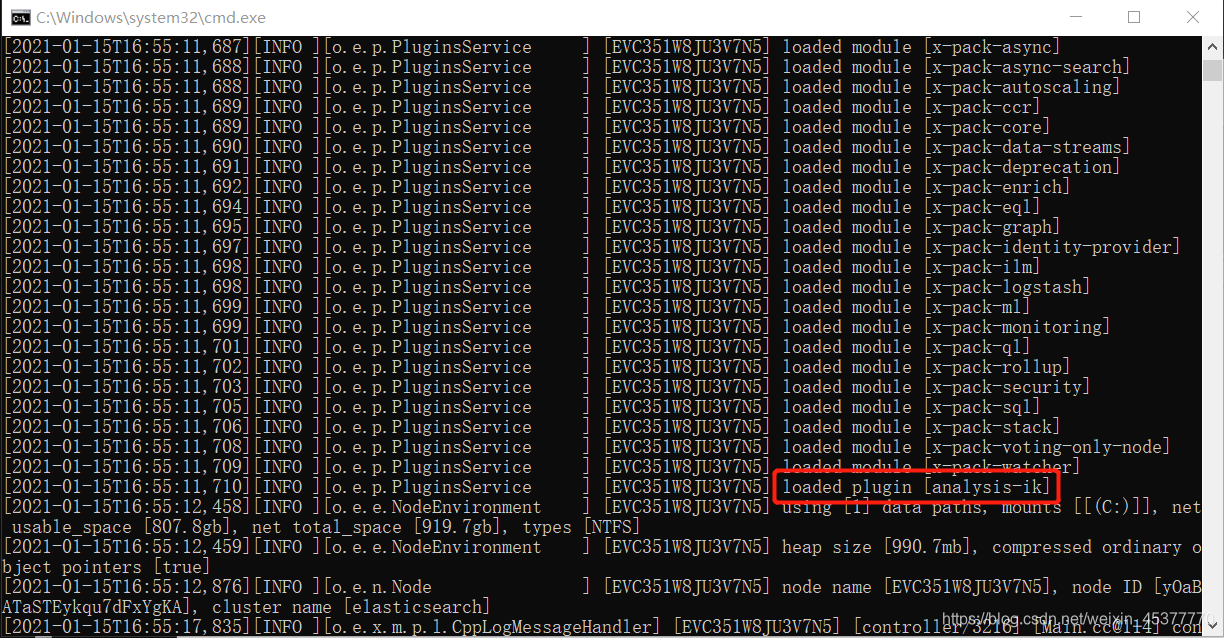
也可以在elasticsearch的bin目录下通过cmd+命令查看加载的插件:elasticsearch-plugin list
- 使用kibana进行测试
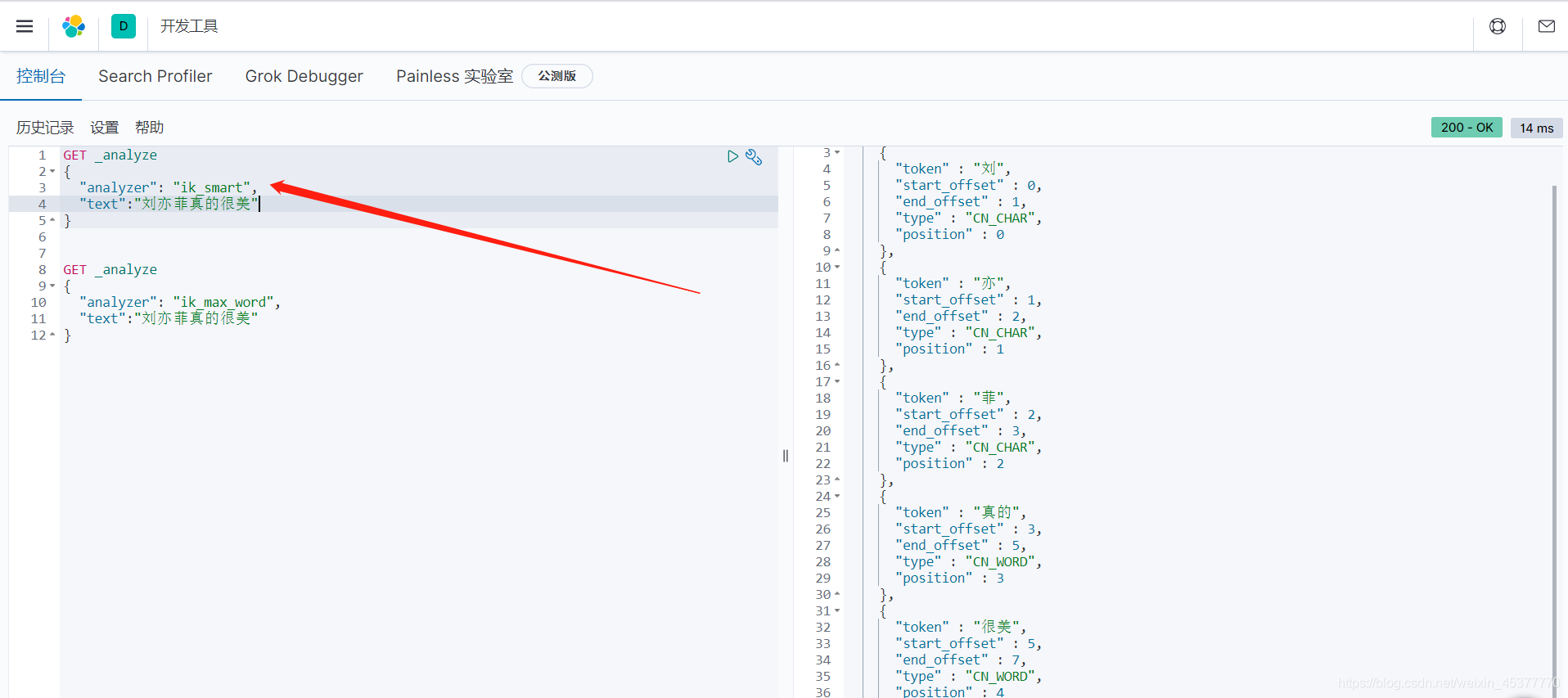
上面说到ik分词器中的 ik_smart 为最少切分, ik_max_word 为最细粒度划分。用一个字符串来试试两者具体的区别
比如说我要搜索 刘亦菲真的很美,两种不同的方式会怎样进行分词
ik_smart 最少切分
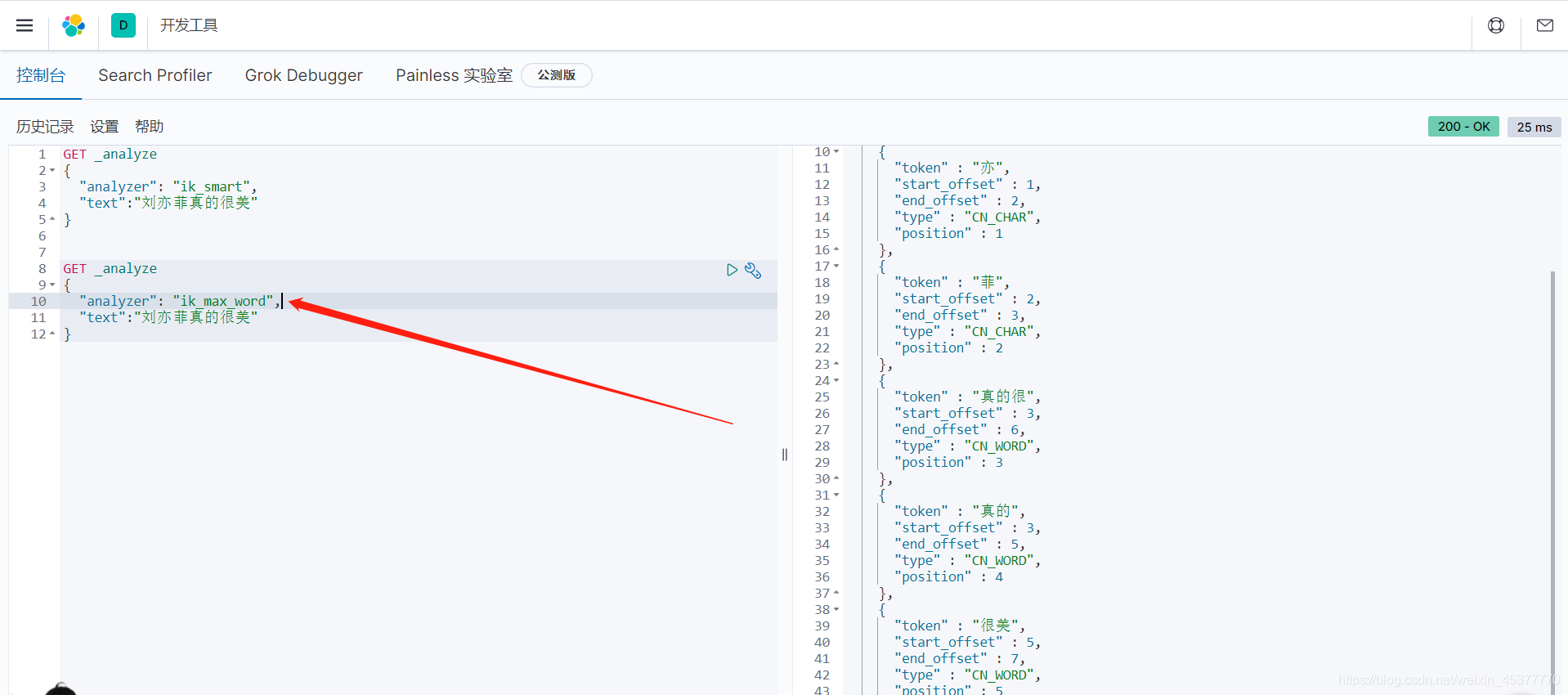
ik_max_word 最细粒度划分
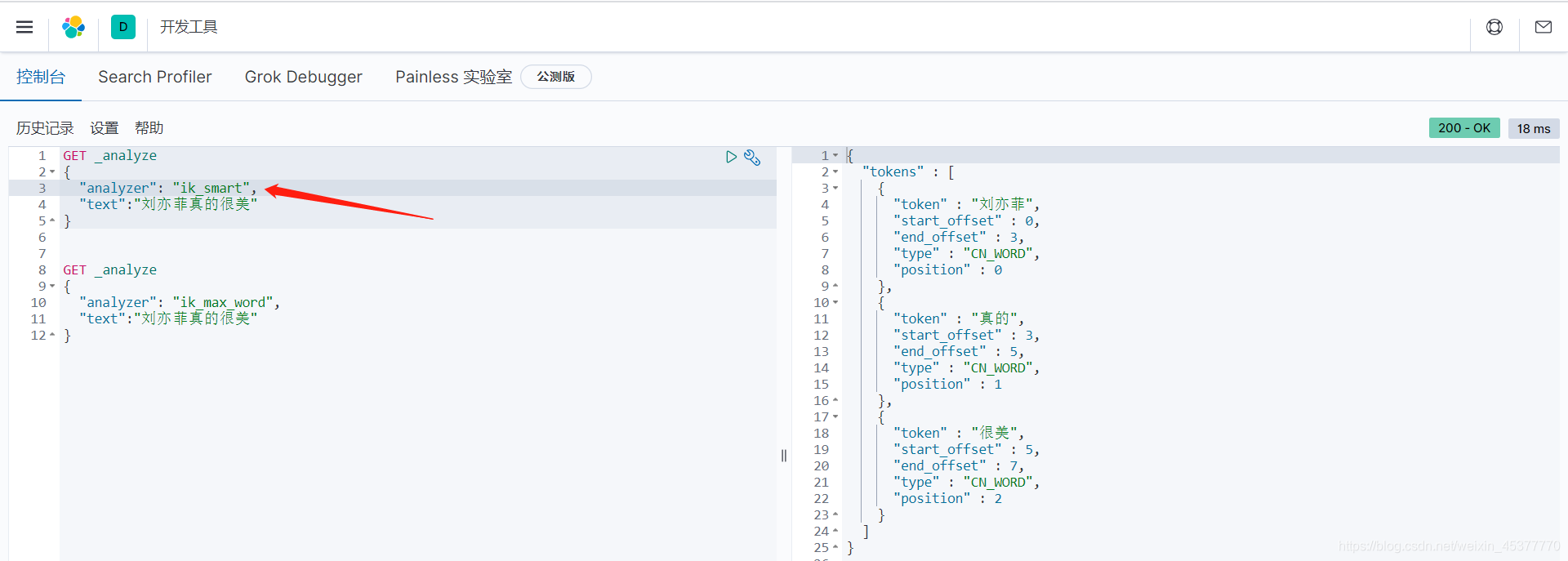
ik_smart 将 刘亦菲真的很美 分为了:刘、亦、菲、真的、很美。五个词
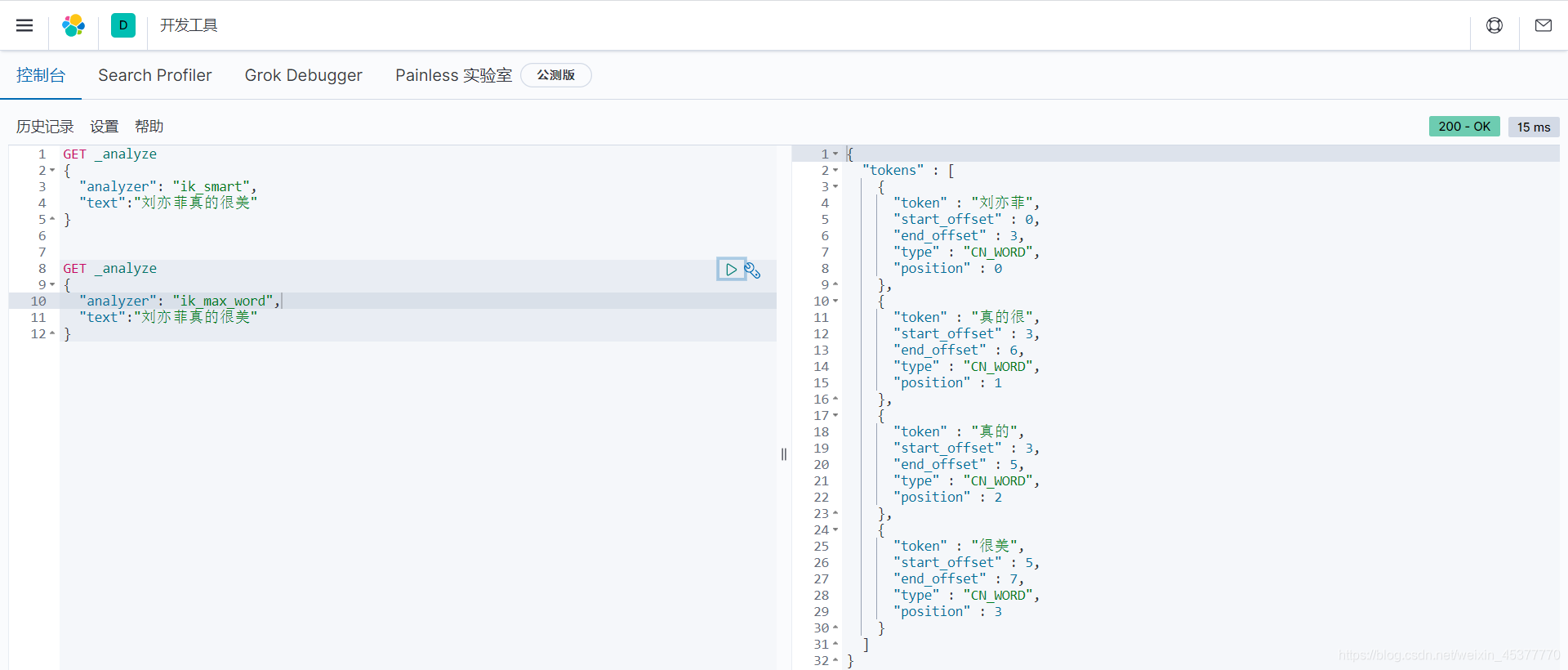
ik_max_word 将 刘亦菲真的很美 分为了:刘、亦、菲、真的、真的很、很美。六个词自定义分词
经过上面的两种测试,我们发现不管以什么方式进行分词,始终把某些我们认为的词组给分成了单个的字
例如上面的词,我想要的是 刘亦菲 ,而不是:刘、亦、菲 三个单独的字。这时候就需要把我们自定义的词组加到ik词典中去
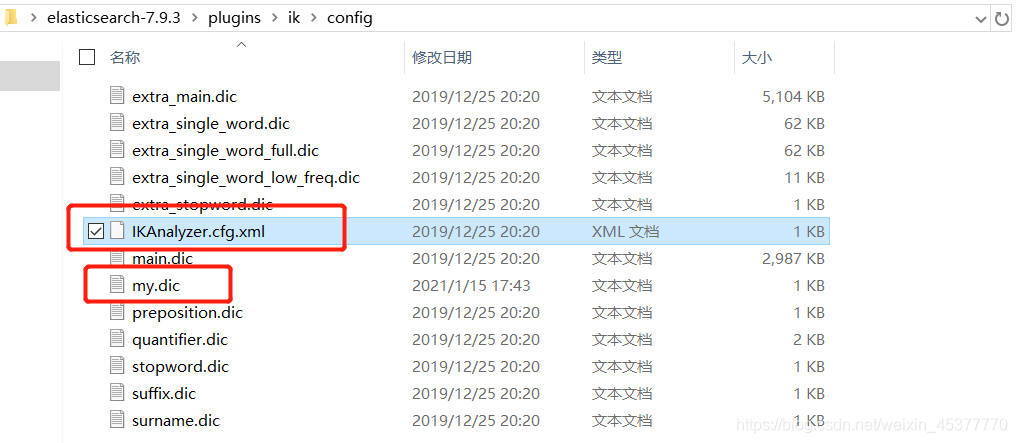
首先进入到elasticsearch-7.9.3\plugins\ik\config 新建一个我们自己的 dic 文件 比如我这里取名为my.dic
打开我们自己的 .dic 文件,并加入我们想要的词语

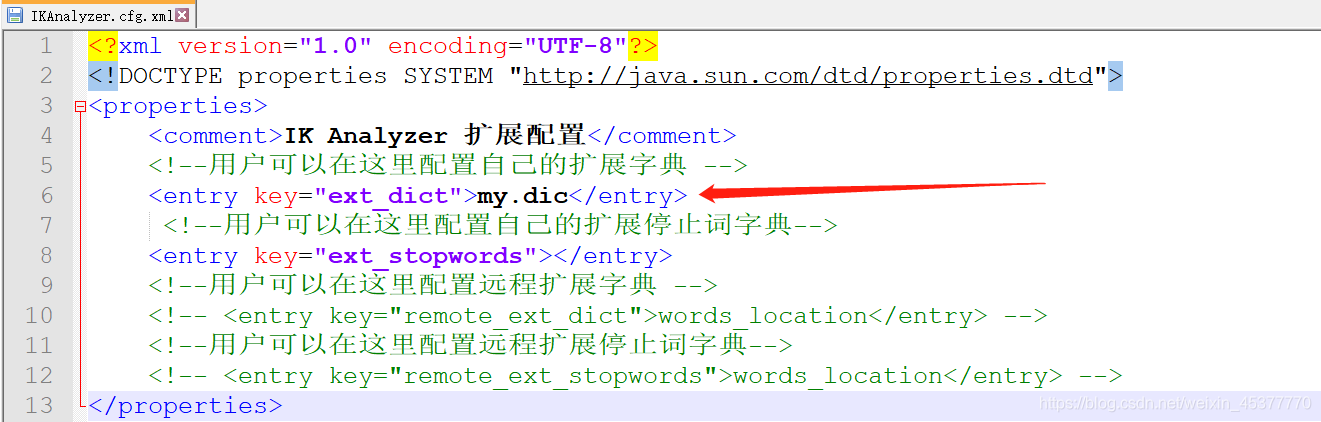
打开config下的 IKAnalyzer.cfg.xml 配置文件 并配置我们刚刚的扩展词组
重启elasticsearch和kibana
- 关闭elasticsearch和kibana的服务窗口
- 分别先运行elasticsearch下bin目录中的 elasticsearch.bat
- 以及kibana的bin目录下 kibana.bat
- 再次打开 http://localhost:5601 进行测试
- ik_smart
- ik_max_word
- 这样就成功啦,就可以按照我们的方式进行分词了